

Python中如何統計文本詞匯出現的次數?
問題描述:
有時在遇到一個文本需要統計文本內詞匯的次數的時候,可以用一個簡單的python程序來實現。
解決方案:
首先需要的是一個文本文件(.txt)格式(文本內詞匯以空格分隔),因為需要的是一個程序,所以要考慮如何將文件打開而不是采用復制粘貼的方式。這時就要用到open()的方式來打開文檔,然后通過read()讀取其中內容,再將詞匯作為key,出現次數作為values存入字典。
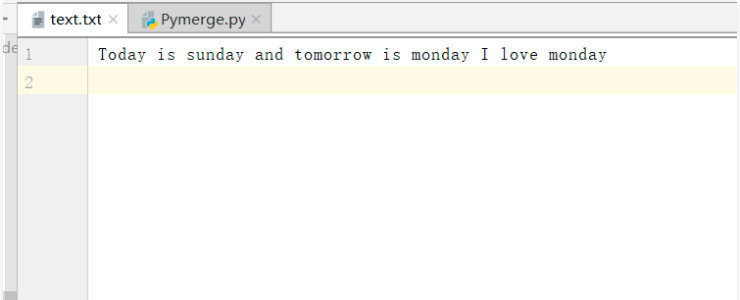

圖 1 txt文件內容
再通過open和read函數來讀取文件:
open_file=open("text.txt")
file_txt=open_file.read()
然后再創建一個空字典,將所有出現的每個詞匯作為key保存到字典中,對文本從開始到結束,循環處理每個詞匯,并將詞匯設置為一個字典的key,將其value設置為1,如果已經存在該詞匯的key,說明該詞匯已經使用過,就將value累積加1。
代碼示例:
def wordcount(readtxt):
readlist = readtxt.split()
dict1={}
for every_world in readlist:
if every_world in dict1:
dict1[every_world] += 1
else:
dict1[every_world] = 1
return dict1
print(wordcount(file_txt))
這里加了def函數把該程序封裝成一個函數。
最后輸出得到詞匯出現的字典:
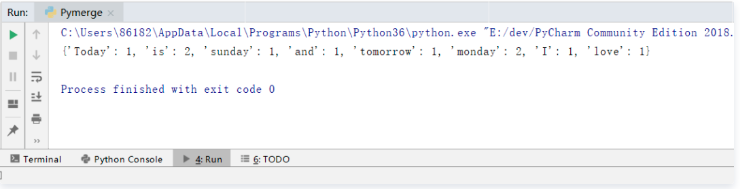
圖 2 形成字典
版權聲明:轉載文章來自公開網絡,版權歸作者本人所有,推送文章除非無法確認,我們都會注明作者和來源。如果出處有誤或侵犯到原作者權益,請與我們聯系刪除或授權事宜。